



This installment of Learning from Machine Learning features Sebastian Raschka, lead AI educator at Lightning AI. As a passionate coder and proponent of open-source software, a contributor to scikit-learn and the creator of the mlxtend library, his code runs in production systems worldwide. But his greatest impact is through his teachings — his books Machine Learning with PyTorch and Scikit-Learn, Machine Learning Q and AI and Build a Large Language Model (From Scratch) have become essential guides for practitioners navigating the complex landscape of modern AI.
Drawing from over a decade of experience building AI systems and teaching at the intersection of academia and industry, Sebastian offers a unique perspective on mastering machine learning fundamentals while staying adaptable in this rapidly evolving field. As Senior Staff Research Engineer at Lighting AI, he continues to bridge the gap between cutting-edge research and practical implementation. In our in-depth discussion in this installment of Learning from Machine Learning, he shared concrete strategies for everything from building reliable production systems to thinking critically about the future of Artificial General Intelligence (AGI).

Our wide-ranging discussion yielded many insights, which I’ve summarized into 13 key lessons:
Start simple and be patient
Learn by doing
Always get a baseline
Embrace change
Find balance between specialized and general systems
Implement from scratch when learning
Use proven libraries in production
It’s the last mile that counts
Use the right tool for the job
Seek diversity when ensembling models
Beware of overconfidence (overconfident models :)
Leverage Large Language Models responsibly
Have fun!
💡 Lessons from a Pioneering Expert💡
1. Start simple and be patient
Approach machine learning with patience, taking concepts step-by-step, in order to build a solid foundation. “You should, make sure you understand the bigger picture and intuition.” Grasp the high-level concepts before getting bogged down in implementation details. Sebastian explains, “I would start with a book or a course and just work through that, almost with a blindness on not getting distracted by other resources.”
“I would start with a book or a course and just work through that, almost with a blindness on not getting distracted by other resources.”
Borrowing from Andrew Ng, Sebastian shares, “If we don’t understand a certain thing, maybe let’s not worry about it. Just yet.” Getting stuck on unclear details can slow you down. Move forward when needed rather than obsessing over gaps. Sebastian expands, “It happens to me all the time. I get distracted by something else, I look it up and then it’s like a rabbit role and you feel, ‘wow, there’s so much to learn’ and then you’re frustrated and overwhelmed because the day only has twenty four hours, you can’t possibly learn it all.”

Remember it’s about “doing one thing at a time, step by step. It’s a marathon, not a sprint.” For early data scientists, he stresses building strong fundamentals before diving into the specifics of advanced techniques.
2. Learn by doing
“Finding a project you’re interested in is the best way to get involved in machine learning and to learn new skills.” He recalled getting hooked while building a fantasy sports predictor, combining his soccer fandom with honing his data abilities. Sebastian explains, “That’s how I taught myself pandas.” Tackling hands-on projects and solving real problems that you feel passionate about accelerates learning.

My first project in machine learning… was a fun one… I was working on fantasy sports predictions back then. I was a big soccer fan. Based on that I built machine learning classifiers with scikit-learn, very simple ones, to basically predict [who] the promising players were, and that was very interesting as an exercise because that’s how I taught myself pandas… I tried to automate as much as possible, so I was also trying to do some simple NLP, going through news articles, basically predicting the sentiment and extracting names from players who were injured and these types of things. It was very challenging, but it was a very good exercise to learn data processing and implementing simple things.”
3. Always get a baseline
When beginning a new ML project you should always find some baseline performance. For example when starting a text classification project, Sebastian says, “Even if you know more sophisticated techniques, even if it makes sense to use a Large Language Model… Start with a simple logistic regression, maybe a bag of words to get a baseline.”
By building a baseline before trying more advanced techniques you can get a better understanding of the problem and the data. If you run into issues when implementing more advanced techniques, having a baseline model where you already read and processed the data can help debug more complex models. If an advanced model underperforms the baseline, it may be an indicator that there are data issues rather than model limitations.

“I would say always start with [simple techniques] even if you know more sophisticated techniques if we go back to what we talked about with large language models even if it makes more sense for a classification problem to fine-tune a large language model for that, I would start… with a simple logistic regression classifier, maybe bag-of-words model to just get a baseline. Use something where you are confident, it’s very simple and it works, let’s say using scikit-learn before trying the more complicated things. It’s not only because we don’t want to use the complicated things because the simple ones are efficient, it’s more about also even checking our solutions like if our fine-tuned model or let’s say BERT or LLM performs worse than the logistic regression classifier maybe we have a bug in our code, maybe we didn’t process the input correctly, [maybe we didn’t] tokenize it correctly - it’s always a good idea to really start simple and then increasingly get complicated or improve - let’s say improve by adding things instead of starting complicated and then trying to debug the complicated solution to find out where the error is essentially.”
4. Embrace change
The field is changing quickly. While it’s important to start slow and take things step by step it is equally important to stay flexible and open to adopting new methods and ideas.
Sebastian stresses the importance of adaptability amid relentless change. “Things change completely. We were using [Generative Adversarial Networks] GANs two years ago and now we’re using diffusion models… [be] open to change.” Machine learning rewards the nimble. He emphasizes being open to new experiences both in machine learning and life.
5. Find balance between specialized and general systems
The pursuit of Artificial General Intelligence (AGI) is a worthy goal but specialized systems often provide better results. Depending on the use case, a specialized system may be more appropriate than a one-size-fits-all approach. Sebastian discusses how systems may be a combination of smaller models where the first model is used to determine which specialized model the task should be directed to.
Regardless, the pursuit for AGI is an incredible motivator and has led to many breakthroughs. As Sebastian explains, the quest for AGI pushed breakthroughs like Deepmind’s AlphaGo beating the best humans at Go. And while AlphaGo itself may not be directly useful, “it ultimately led to AlphaFold, the first version, for protein structure prediction.”
The dream of AGI serves as inspiration, but specialized systems focused on narrow domains currently provide the most value. Still, the race towards AGI has led to advances that found practical application.
“I think no one knows how far we are from AGI… I think there’s a lot more hype around AGI it appears closer than before of course because we have these models. There are people though who say okay this is the totally wrong approach we need something completely different if we want to get AGI no one knows what that approach looks like so it’s really hard to say…
…The thing though what I always find interesting is do we need AGI more like a philosophical question… AGI is useful as the motivation. I think it motivates a lot of people to work on AI to make that progress. I think without AGI we wouldn’t have things like AlphaGo where they had the breakthrough they basically beat the best player at go… how is that useful - I would say maybe go and chess engines are not useful but I think it ultimately led to AlphaFold the first version for protein structure prediction and then AlphaFold 2 which is not based on large language models but uses large language models. So in that case I think without large language models and without the desire maybe to develop AGI we wouldn’t have all these very useful things in the Natural Sciences and so my question is do we need AGI or do we really just need good models for special purposes…”
6. When learning, implement from scratch
Coding algorithms without depending on external libraries (e.g., using just Python) helps build a better understanding of the underlying concepts. Sebastian explains, “Implementing algorithms from scratch helps build intuition and peel back the layers to make things more understandable.”
“Implementing algorithms from scratch helps build intuition and peel back the layers to make things more understandable.”
Fortunately, Sebastian shares many of these educational implementations through posts and tutorials. We dove into Sebastian’s breakdown of Self-Attention of LLMs from Scratch where he breaks down the importance of the “self-attention” mechanism which is a cornerstone of both transformers and stable-diffusion.
7. In production, don’t reinvent the wheel!
In real world applications, you don’t have to reinvent the wheel. Sebastian expands for things that already exist, “I think that is a lot of work and also risky.” While building from scratch is enlightening, production-ready applications rely on proven, battle-tested libraries.

8. It’s the last mile that counts
Getting a model to relatively high performance is much easier than squeezing out the last few percentage points to reach extremely high performance. But that final push is vital — it’s the difference between an impressive prototype and a production-ready system. Even if rapid progress was made initially, the final seemingly marginal gains to reach “perfection” are very challenging.
Even if rapid progress was made initially, the final seemingly marginal gains to reach “perfection” are very challenging.
Sebastian uses self-driving cars to drive this point across. “Five years ago, they already had pretty impressive demos… but I do think it’s the last few percent that are crucial.” He continues, “Five years ago, it was almost let’s say 95% there, almost ready. Now five years later, we are maybe 97–98%, but can we get the last remaining percent points to really nail it and have them on the road reliably.”
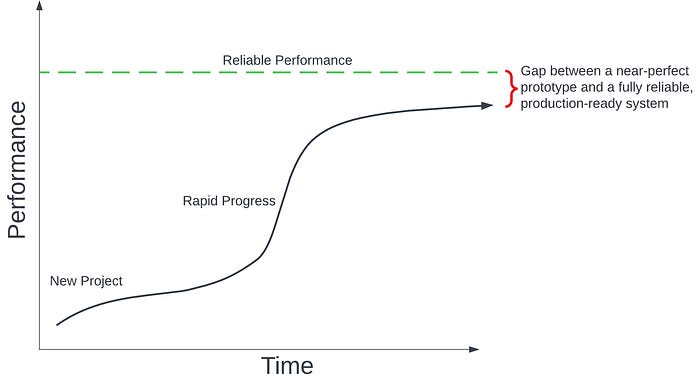
Sebastian draws a comparison between ChatGPT and Self-Driving cars. While astounding demos of both technologies exist, getting those last few percentage points of performance to reach full reliability has proven difficult and vital.
9. Use the right tool for the job
Sebastian cautions against forcing ML everywhere, stating “If you have a hammer, everything looks like a nail… the question becomes when to use AI and when not to use AI.” The trick is often knowing when to use rules, ML, or other tools. Sebastian shares, “Right now, we are using AI for a lot of things because it is exciting, and we want to see how far we can push it until it breaks or doesn’t work… sometimes we have nonsensical applications of AI because of that.”
Automation has limits. Sometimes rules and human expertise outperform AI. It’s important to pick the best approach for each task. Just because we can use AI/ML as a solution doesn’t mean we should for every problem.
“[There’s] a saying if you have a hammer everything looks like a nail, and I think this is right now a little bit true with ChatGPT because we just have fun with it… let me see if it can do this and that but it doesn’t mean we should be using it for everything… now the question is basically the next level… when to use AI and when not to use AI… because right now we are using AI for a lot of things because it’s exciting and we want to see how far we can push it until it let’s say breaks so it doesn’t work but sometimes we have nonsensical applications of AI because of that. …like training a neural network that can do calculation… but we wouldn’t let it do the math matrix multiplication itself because you know it’s non-deterministic in a sense so you don’t know if it’s going to be correct or not depending on your inputs and there are definite rules that we can use so why approximate when we can have it accurate”
10. Seek Diversity in Model Ensembles
Ensemble methods like model stacking can improve prediction robustness, but diversity is key — combining correlated models that make similar types of errors won’t provide much upside.
As Sebastian explains, “Building an ensemble of different methods is usually something to make [models] more robust and [produce] accurate predictions. And ensemble methods usually work best if you have an ensemble of different methods. If there’s no correlation in terms of how they work. So they are not redundant, basically.”
The goal is to have a diverse set of complementary models. For example, you might ensemble a random forest model with a neural network, or a gradient boosting machine with a k-nearest neighbors model. Stacking models that have high diversity improves the ensemble’s ability to correct errors made by individual models.
So when building ensembles, seek diversity — use different algorithms, different feature representations, different hyperparameters, etc. Correlation analysis of predictions can help identify which models provide unique signal vs redundancy. The key is having a complementary set of models in the ensemble, not just combining slight variations of the same approach.
“…building an ensemble of different methods is usually something to improve how you can make more robust and accurate predictions and ensemble methods usually work best if you have an ensemble of different methods — if there’s no correlation in terms of how they work. So they are not redundant basically. That is also one argument why it makes sense to maybe approach the problem from different angles to produce totally different systems that we can then combine.”
Models with varying strengths and weaknesses can effectively counterbalance each other’s shortcomings, leading to more reliable overall performance.
11. Beware of overconfidence
“There’s a whole branch of research on [how] neural networks are typically overconfident on out of distribution data.” ML predictions can be misleadingly overconfident on unusual data. Sebastian describes, “So what happens is if you have data that is slightly different from your training data or let’s say out of the distribution, the network will if you program it to give a confidence score as part of the output, this score for the data where it’s especially wrong is usually over confident… which makes it even more dangerous.” Validate reliability before deployment, rather than blindly trusting in confidence scores. Confidence scores can often be high for wrong predictions making them misleading for unfamiliar data.
Validate reliability before deployment, rather than blindly trusting in confidence scores.
To combat overconfidence in practice, start by establishing multiple validation sets that include both edge cases and known out-of-distribution examples, keeping a separate test set for final verification. A robust monitoring system is equally crucial — track confidence scores over time, monitor the rate of high-confidence errors, set up alerts for unusual confidence patterns, and maintain comprehensive logs of all predictions and their associated confidence scores.
For production systems, implement fallback mechanisms including simpler backup models, clear business rules for low-confidence cases, and human review processes for highly uncertain predictions. Regular maintenance is essential: as new data becomes available it may be worthwhile to retrain models, adjust confidence thresholds based on real-world performance, fine-tune out-of-distribution detection parameters, and continuously validate model calibration. These practices help ensure your models remain reliable and self-aware of their limitations, rather than falling into the trap of overconfidence.
12. Leverage Large Language Models responsibly
ChatGPT (and other generative models) are good brainstorming partners and can be used for ideation when “it doesn’t need to be 100% correct.” Sebastian warns that the model’s output should not be used as the final output. Large language models can generate text to accelerate drafting but require human refinement. It’s important to be fully aware of the limitations of the LLMs.
13. Remember to have fun!
“Make sure you have fun. Try not to do all at once.” Learning is most effective and sustainable when it’s enjoyable. Passion for the process itself, not just outcomes, leads to mastery. Sebastian emphasizes to remember to recharge and connect with others who inspire you. Sebastian shares, “Whatever you do, have fun, enjoy, share the joy… things are sometimes complicated and work can be intense. We want to get things done, but don’t forget… to stop and enjoy sometimes.”
Conclusion
While the field’s rapid advancement and complexity can be overwhelming, Sebastian offers a clear path forward: build rock-solid fundamentals, always start with baseline models, and maintain systematic approaches to combat common pitfalls. He advocates for implementing algorithms from scratch before using high-level, optimized libraries to ensure deep understanding. He offers practical strategies — such as including diversity in ensemble models, critically assessing model confidence, and recognizing the difficulty of the “last mile” — for developing reliable and dependable production-quality AI systems.
Sebastian stresses that mastering machine learning isn’t about chasing every new development. Instead, it’s about building a strong foundation that enables you to evaluate and adapt to meaningful advances. By focusing on core principles while remaining open to new techniques, we can build the confidence to face increasingly complex challenges. Whether you’re implementing your first machine learning project or architecting enterprise-scale AI systems, the key is to embrace the learning process: start simple, evaluate thoroughly, and never stop questioning your assumptions. In a field that seems to reinvent itself almost daily, these timeless principles are our most reliable guides.
Listen on your favorite podcast platform:
https://rss.com/podcasts/learning-from-machine-learning/
Resources to learn more about Sebastian Raschka and his work:
Machine Learning with Pytorch and Scikit-Learn
Resources to learn more about Learning from Machine Learning and the host: https://www.linkedin.com/company/learning-from-machine-learning
https://www.linkedin.com/in/sethplevine/
https://medium.com/@levine.seth.p
References from Episode
https://scikit-learn.org/stable/
http://rasbt.github.io/mlxtend/
https://github.com/BioPandas/biopandas
Understanding and Coding the Self-Attention Mechanism of Large Language Models From Scratch
Andrew Ng - https://www.andrewng.org/
Andrej Karpathy - https://karpathy.ai/
Paige Bailey - https://github.com/dynamicwebpaige
Contents
01:15 - Career Background
05:18 - Industry vs. Academia
08:18 - First Project in ML
15:04 - Open Source Projects Involvement
20:00 - Machine Learning: Q&AI
24:18 - ChatGPT as Brainstorm Assistant
25:38 - Hype vs. Reality
27:55 - AGI
31:00 - Use Cases for Generative Models
34:01 - Should the goal to be to replicate human intelligence?
39:18 - Delegating Tasks using LLM
42:26 - ML Models are overconfident on Out of Distribution
44:54 - Responsible AI and ML
45:59 - Complexity of ML Systems
47:26 - Trend for ML Practitioners to move to AI Ethics
49:27 - What advice would you give to someone just starting out?
52:20 - Advice that you’ve received that has helped you
54:08 - Andrew Ng Advice
55:20 - Exercise of Implementing Algorithms from Scratch
59:00 - Who else has influenced you?
01:01:18 - Production and Real-World Applications - Don’t reinvent the wheel
01:03:00 - What has a career in ML taught you about life?





